Gaussian Mixture Model¶
This tutorial demonstrates how to marginalize out discrete latent variables in Pyro through the motivating example of a mixture model. We’ll focus on the mechanics of parallel enumeration, keeping the model simple by training a trivial 1-D Gaussian model on a tiny 5-point dataset. See also the enumeration tutorial for a broader introduction to parallel enumeration.
Table of contents¶
[24]:
import os
from collections import defaultdict
import torch
import numpy as np
import scipy.stats
from torch.distributions import constraints
from matplotlib import pyplot
%matplotlib inline
import pyro
import pyro.distributions as dist
from pyro import poutine
from pyro.infer.autoguide import AutoDelta
from pyro.optim import Adam
from pyro.infer import SVI, TraceEnum_ELBO, config_enumerate, infer_discrete
smoke_test = "CI" in os.environ
assert pyro.__version__.startswith('1.9.1')
Overview¶
Pyro’s TraceEnum_ELBO can automatically marginalize out variables in both the guide and the model. When enumerating guide variables, Pyro can either enumerate sequentially (which is useful if the variables determine downstream control flow), or enumerate in parallel by allocating a new tensor dimension and using nonstandard evaluation to create a tensor of possible values at the variable’s sample site. These nonstandard values are then replayed in the model. When enumerating variables in the model, the variables must be enumerated in parallel and must not appear in the guide. Mathematically, guide-side enumeration simply reduces variance in a stochastic ELBO by enumerating all values, whereas model-side enumeration avoids an application of Jensen’s inequality by exactly marginalizing out a variable.
Here is our tiny dataset. It has five points.
[25]:
data = torch.tensor([0.0, 1.0, 10.0, 11.0, 12.0])
Training a MAP estimator¶
Let’s start by learning model parameters weights, locs, and scale given priors and data. We will learn point estimates of these using an AutoDelta guide (named after its delta distributions). Our model will learn global mixture weights, the location of each mixture component, and a shared scale that is common to both components. During inference,
TraceEnum_ELBO will marginalize out the assignments of datapoints to clusters.
[26]:
K = 2 # Fixed number of components.
@config_enumerate
def model(data):
# Global variables.
weights = pyro.sample("weights", dist.Dirichlet(0.5 * torch.ones(K)))
scale = pyro.sample("scale", dist.LogNormal(0.0, 2.0))
with pyro.plate("components", K):
locs = pyro.sample("locs", dist.Normal(0.0, 10.0))
with pyro.plate("data", len(data)):
# Local variables.
assignment = pyro.sample("assignment", dist.Categorical(weights))
pyro.sample("obs", dist.Normal(locs[assignment], scale), obs=data)
To run inference with this (model,guide) pair, we use Pyro’s config_enumerate() handler to enumerate over all assignments in each iteration. Since we’ve wrapped the batched Categorical assignments in a pyro.plate indepencence context, this enumeration can happen in parallel: we enumerate only 2 possibilites, rather than 2**len(data) = 32. Finally, to
use the parallel version of enumeration, we inform Pyro that we’re only using a single plate via max_plate_nesting=1; this lets Pyro know that we’re using the rightmost dimension plate and that Pyro can use any other dimension for parallelization.
[27]:
optim = pyro.optim.Adam({"lr": 0.1, "betas": [0.8, 0.99]})
elbo = TraceEnum_ELBO(max_plate_nesting=1)
Before inference we’ll initialize to plausible values. Mixture models are very succeptible to local modes. A common approach is to choose the best among many random initializations, where the cluster means are initialized from random subsamples of the data. Since we’re using an AutoDelta guide, we can initialize by defining a custom init_loc_fn().
[28]:
def init_loc_fn(site):
if site["name"] == "weights":
# Initialize weights to uniform.
return torch.ones(K) / K
if site["name"] == "scale":
return (data.var() / 2).sqrt()
if site["name"] == "locs":
return data[torch.multinomial(torch.ones(len(data)) / len(data), K)]
raise ValueError(site["name"])
def initialize(seed):
global global_guide, svi
pyro.set_rng_seed(seed)
pyro.clear_param_store()
global_guide = AutoDelta(
poutine.block(model, expose=["weights", "locs", "scale"]),
init_loc_fn=init_loc_fn,
)
svi = SVI(model, global_guide, optim, loss=elbo)
return svi.loss(model, global_guide, data)
# Choose the best among 100 random initializations.
loss, seed = min((initialize(seed), seed) for seed in range(100))
initialize(seed)
print(f"seed = {seed}, initial_loss = {loss}")
seed = 13, initial_loss = 25.665584564208984
During training, we’ll collect both losses and gradient norms to monitor convergence. We can do this using PyTorch’s .register_hook() method.
[29]:
# Register hooks to monitor gradient norms.
gradient_norms = defaultdict(list)
for name, value in pyro.get_param_store().named_parameters():
value.register_hook(
lambda g, name=name: gradient_norms[name].append(g.norm().item())
)
losses = []
for i in range(200 if not smoke_test else 2):
loss = svi.step(data)
losses.append(loss)
print("." if i % 100 else "\n", end="")
...................................................................................................
...................................................................................................
[30]:
pyplot.figure(figsize=(10, 3), dpi=100).set_facecolor("white")
pyplot.plot(losses)
pyplot.xlabel("iters")
pyplot.ylabel("loss")
pyplot.yscale("log")
pyplot.title("Convergence of SVI");
[31]:
pyplot.figure(figsize=(10, 4), dpi=100).set_facecolor("white")
for name, grad_norms in gradient_norms.items():
pyplot.plot(grad_norms, label=name)
pyplot.xlabel("iters")
pyplot.ylabel("gradient norm")
pyplot.yscale("log")
pyplot.legend(loc="best")
pyplot.title("Gradient norms during SVI");
Here are the learned parameters:
[32]:
map_estimates = global_guide(data)
weights = map_estimates["weights"]
locs = map_estimates["locs"]
scale = map_estimates["scale"]
print(f"weights = {weights.data.numpy()}")
print(f"locs = {locs.data.numpy()}")
print(f"scale = {scale.data.numpy()}")
weights = [0.625 0.375]
locs = [10.984464 0.49901518]
scale = 0.6514337062835693
The model’s weights are as expected, with about 2/5 of the data in the first component and 3/5 in the second component. Next let’s visualize the mixture model.
[33]:
X = np.arange(-3, 15, 0.1)
Y1 = weights[0].item() * scipy.stats.norm.pdf((X - locs[0].item()) / scale.item())
Y2 = weights[1].item() * scipy.stats.norm.pdf((X - locs[1].item()) / scale.item())
pyplot.figure(figsize=(10, 4), dpi=100).set_facecolor("white")
pyplot.plot(X, Y1, "r-")
pyplot.plot(X, Y2, "b-")
pyplot.plot(X, Y1 + Y2, "k--")
pyplot.plot(data.data.numpy(), np.zeros(len(data)), "k*")
pyplot.title("Density of two-component mixture model")
pyplot.ylabel("probability density");
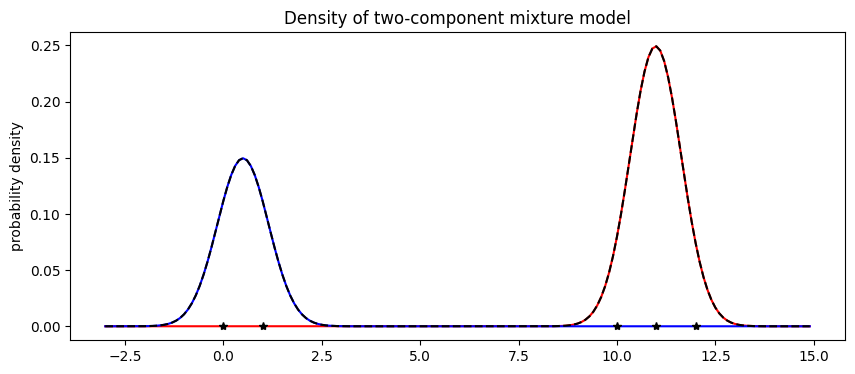
Finally note that optimization with mixture models is non-convex and can often get stuck in local optima. For example in this tutorial, we observed that the mixture model gets stuck in an everthing-in-one-cluster hypothesis if scale is initialized to be too large.
Serving the model: predicting membership¶
Now that we’ve trained a mixture model, we might want to use the model as a classifier. During training we marginalized out the assignment variables in the model. While this provides fast convergence, it prevents us from reading the cluster assignments from the guide. We’ll discuss two options for treating the model as a classifier: first using infer_discrete (much faster) and second by training a secondary guide using enumeration inside SVI (slower but more general).
Predicting membership using discrete inference¶
The fastest way to predict membership is to use the infer_discrete handler, together with trace and replay. Let’s start out with a MAP classifier, setting infer_discrete’s temperature parameter to zero. For a deeper look at effect handlers like trace, replay, and infer_discrete, see the effect handler tutorial.
[34]:
guide_trace = poutine.trace(global_guide).get_trace(data) # record the globals
trained_model = poutine.replay(model, trace=guide_trace) # replay the globals
def classifier(data, temperature=0):
inferred_model = infer_discrete(
trained_model, temperature=temperature, first_available_dim=-2
) # avoid conflict with data plate
trace = poutine.trace(inferred_model).get_trace(data)
return trace.nodes["assignment"]["value"]
print(classifier(data))
tensor([1, 1, 0, 0, 0])
Indeed we can run this classifer on new data
[35]:
new_data = torch.arange(-3, 15, 0.1)
assignment = classifier(new_data)
pyplot.figure(figsize=(8, 2), dpi=100).set_facecolor("white")
pyplot.plot(new_data.numpy(), assignment.numpy())
pyplot.title("MAP assignment")
pyplot.xlabel("data value")
pyplot.ylabel("class assignment");
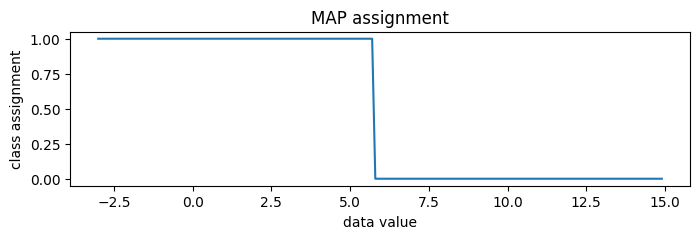
To generate random posterior assignments rather than MAP assignments, we could set temperature=1.
[36]:
print(classifier(data, temperature=1))
tensor([1, 1, 0, 0, 0])
Since the classes are very well separated, we zoom in to the boundary between classes, around 5.75.
[37]:
new_data = torch.arange(5.5, 6.0, 0.005)
assignment = classifier(new_data, temperature=1)
pyplot.figure(figsize=(8, 2), dpi=100).set_facecolor("white")
pyplot.plot(new_data.numpy(), assignment.numpy(), "x", color="C0")
pyplot.title("Random posterior assignment")
pyplot.xlabel("data value")
pyplot.ylabel("class assignment");
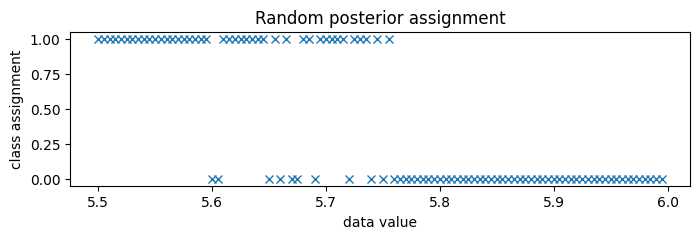
Predicting membership by enumerating in the guide¶
A second way to predict class membership is to enumerate in the guide. This doesn’t work well for serving classifier models, since we need to run stochastic optimization for each new input data batch, but it is more general in that it can be embedded in larger variational models.
To read cluster assignments from the guide, we’ll define a new full_guide that fits both global parameters (as above) and local parameters (which were previously marginalized out). Since we’ve already learned good values for the global variables, we will block SVI from updating those by using poutine.block.
[38]:
@config_enumerate
def full_guide(data):
# Global variables.
with poutine.block(
hide_types=["param"]
): # Keep our learned values of global parameters.
global_guide(data)
# Local variables.
with pyro.plate("data", len(data)):
assignment_probs = pyro.param(
"assignment_probs",
torch.ones(len(data), K) / K,
constraint=constraints.simplex,
)
pyro.sample("assignment", dist.Categorical(assignment_probs))
[39]:
optim = pyro.optim.Adam({"lr": 0.2, "betas": [0.8, 0.99]})
elbo = TraceEnum_ELBO(max_plate_nesting=1)
svi = SVI(model, full_guide, optim, loss=elbo)
# Register hooks to monitor gradient norms.
gradient_norms = defaultdict(list)
svi.loss(model, full_guide, data) # Initializes param store.
for name, value in pyro.get_param_store().named_parameters():
value.register_hook(
lambda g, name=name: gradient_norms[name].append(g.norm().item())
)
losses = []
for i in range(200 if not smoke_test else 2):
loss = svi.step(data)
losses.append(loss)
print("." if i % 100 else "\n", end="")
...................................................................................................
...................................................................................................
[40]:
pyplot.figure(figsize=(10, 3), dpi=100).set_facecolor("white")
pyplot.plot(losses)
pyplot.xlabel("iters")
pyplot.ylabel("loss")
pyplot.yscale("log")
pyplot.title("Convergence of SVI");
[41]:
pyplot.figure(figsize=(10, 4), dpi=100).set_facecolor("white")
for name, grad_norms in gradient_norms.items():
pyplot.plot(grad_norms, label=name)
pyplot.xlabel("iters")
pyplot.ylabel("gradient norm")
pyplot.yscale("log")
pyplot.legend(loc="best")
pyplot.title("Gradient norms during SVI");
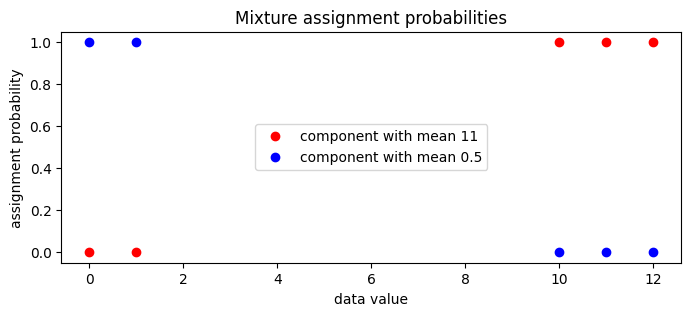
We can now examine the guide’s local assignment_probs variable.
[42]:
assignment_probs = pyro.param("assignment_probs")
pyplot.figure(figsize=(8, 3), dpi=100).set_facecolor("white")
pyplot.plot(
data.data.numpy(),
assignment_probs.data.numpy()[:, 0],
"ro",
label=f"component with mean {locs[0]:0.2g}",
)
pyplot.plot(
data.data.numpy(),
assignment_probs.data.numpy()[:, 1],
"bo",
label=f"component with mean {locs[1]:0.2g}",
)
pyplot.title("Mixture assignment probabilities")
pyplot.xlabel("data value")
pyplot.ylabel("assignment probability")
pyplot.legend(loc="center");
MCMC¶
Next we’ll explore the full posterior over component parameters using collapsed NUTS, i.e. we’ll use NUTS and marginalize out all discrete latent variables.
[43]:
from pyro.infer.mcmc.api import MCMC
from pyro.infer.mcmc import NUTS
pyro.set_rng_seed(2)
kernel = NUTS(model)
mcmc = MCMC(kernel, num_samples=250, warmup_steps=50)
mcmc.run(data)
posterior_samples = mcmc.get_samples()
Sample: 100%|██████████████████████████████████████████| 300/300 [00:12, 23.57it/s, step size=4.38e-01, acc. prob=0.951]
[44]:
X, Y = posterior_samples["locs"].T
[45]:
pyplot.figure(figsize=(8, 8), dpi=100).set_facecolor("white")
h, xs, ys, image = pyplot.hist2d(X.numpy(), Y.numpy(), bins=[20, 20])
pyplot.contour(
np.log(h + 3).T,
extent=[xs.min(), xs.max(), ys.min(), ys.max()],
colors="white",
alpha=0.8,
)
pyplot.title("Posterior density as estimated by collapsed NUTS")
pyplot.xlabel("loc of component 0")
pyplot.ylabel("loc of component 1")
pyplot.tight_layout()
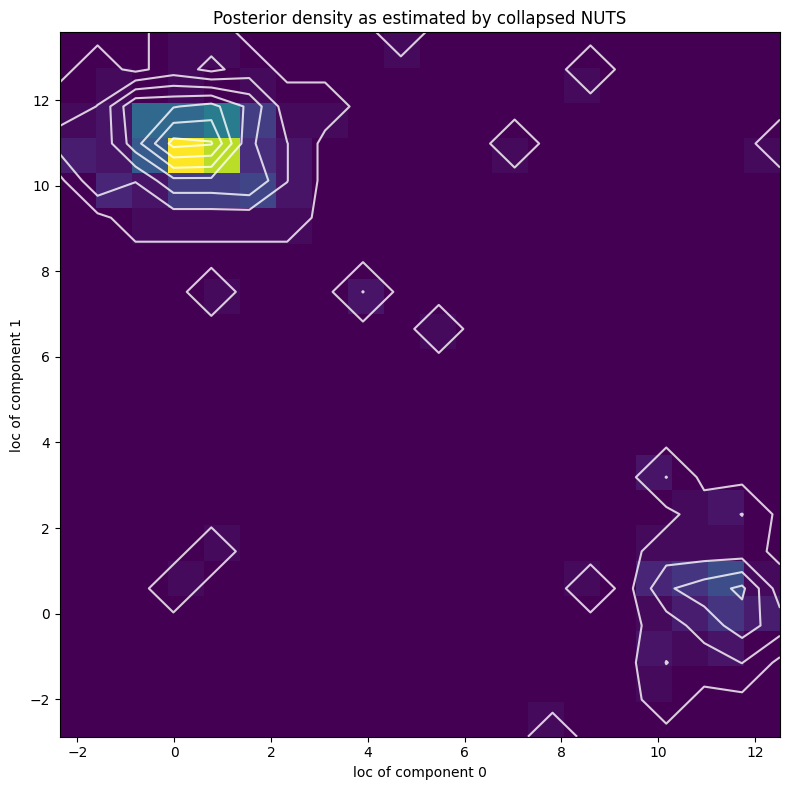
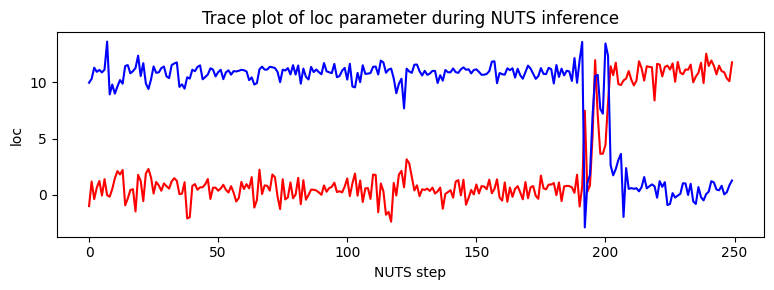
Note that due to nonidentifiability of the mixture components the likelihood landscape has two equally likely modes, near (11,0.5) and (0.5,11). NUTS has difficulty switching between the two modes.
[46]:
pyplot.figure(figsize=(8, 3), dpi=100).set_facecolor("white")
pyplot.plot(X.numpy(), color="red")
pyplot.plot(Y.numpy(), color="blue")
pyplot.xlabel("NUTS step")
pyplot.ylabel("loc")
pyplot.title("Trace plot of loc parameter during NUTS inference")
pyplot.tight_layout()